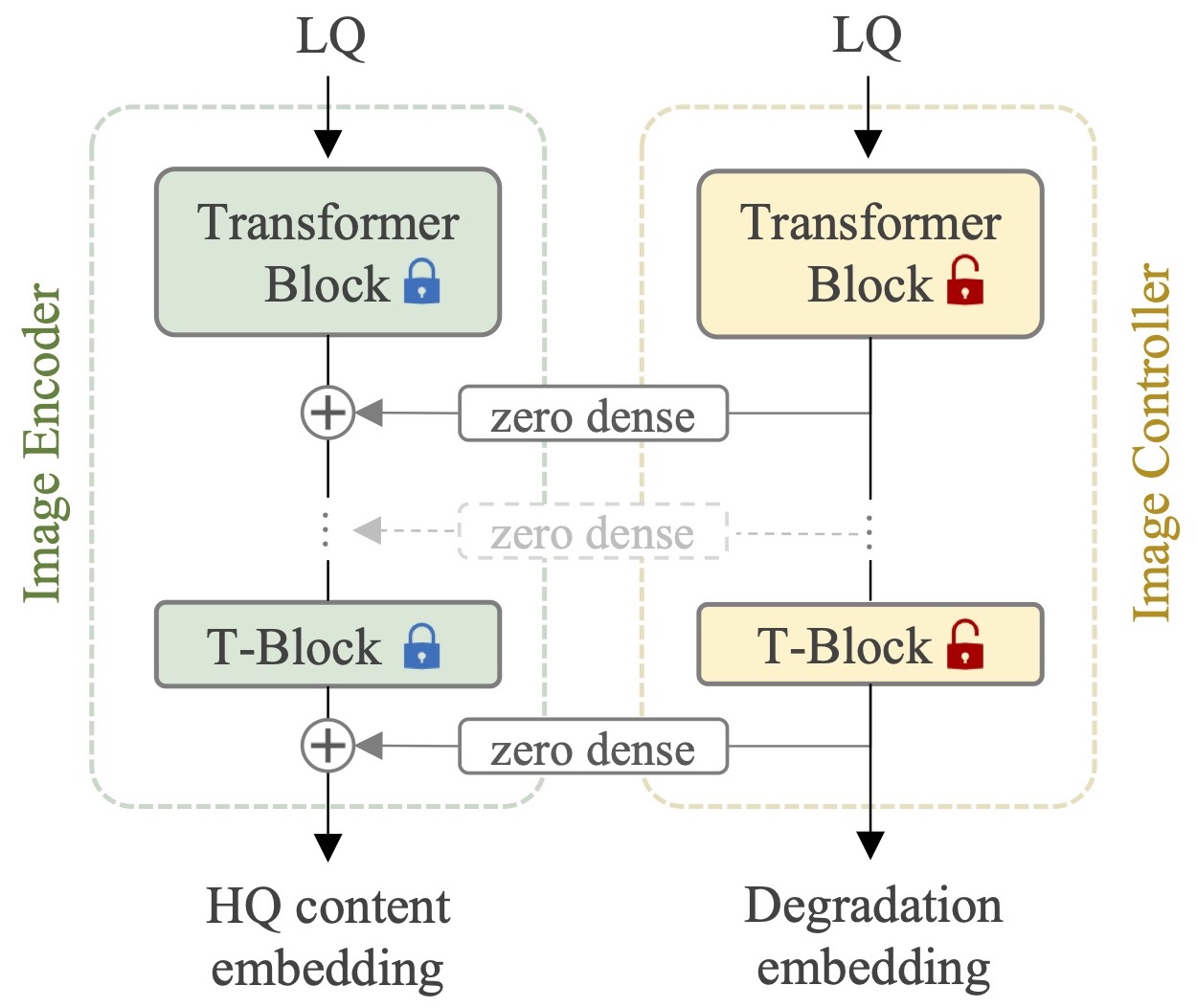
Controller
Controlling the ViT-based image encoder with a trainable controller. The dense connection layers from controller to image encoder are initialized to zero.









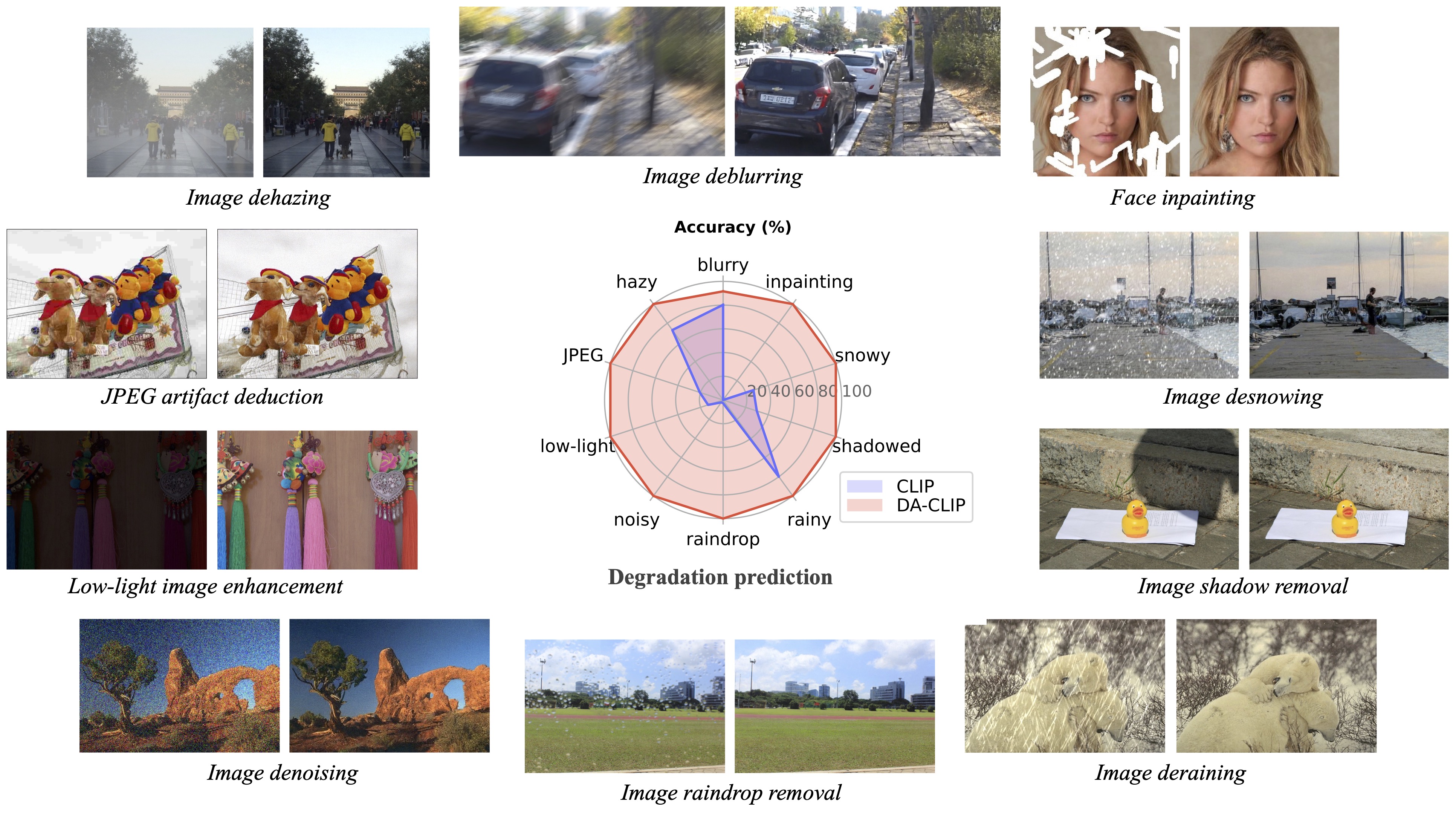
Vision-language models such as CLIP have shown great impact on diverse downstream tasks for zero-shot or label-free predictions. However, when it comes to low-level vision such as image restoration their performance deteriorates dramatically due to corrupted inputs.
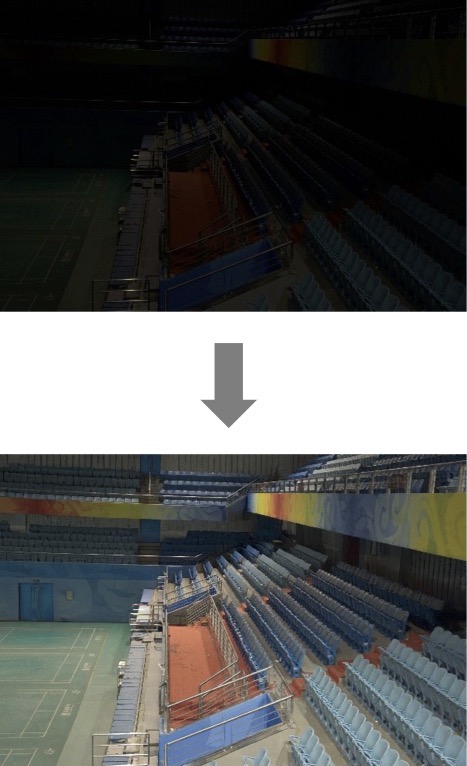
In this paper, we present a degradation-aware vision-language model (DA-CLIP) to better transfer pretrained vision-language models to low-level vision tasks as a multi-task framework for image restoration. More specifically, DA-CLIP trains an additional controller that adapts the fixed CLIP image encoder to predict high-quality feature embeddings. By integrating the embedding into an image restoration network via cross-attention, we are able to pilot the model to learn a high-fidelity image reconstruction. The controller itself will also output a degradation feature that matches the real corruptions of the input, yielding a natural classifier for different degradation types.
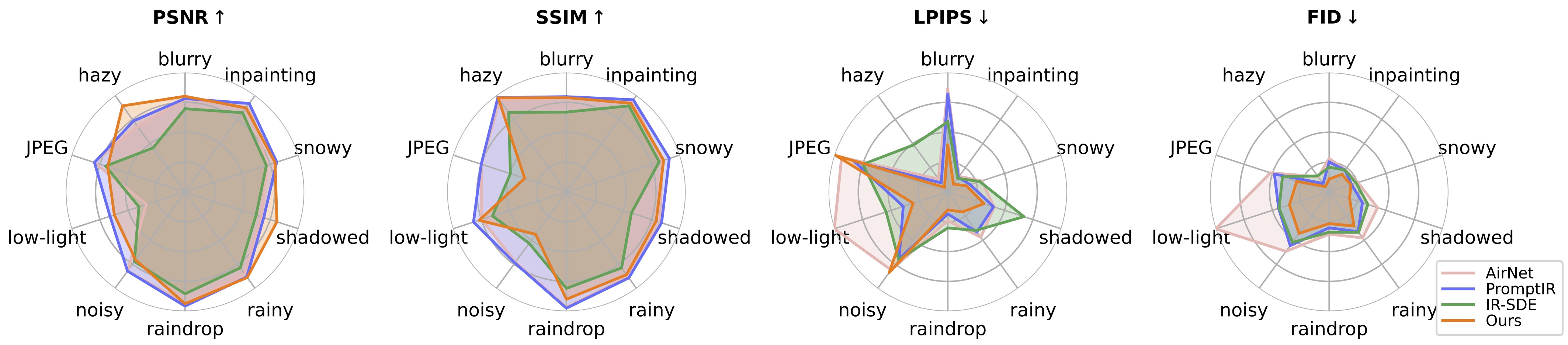
In addition, we construct a mixed degradation dataset with synthetic captions for DA-CLIP training. Our approach advances state-of-the-art performance on both degradation-specific and unified image restoration tasks, showing a promising direction of prompting image restoration with large-scale pretrained vision-language models.
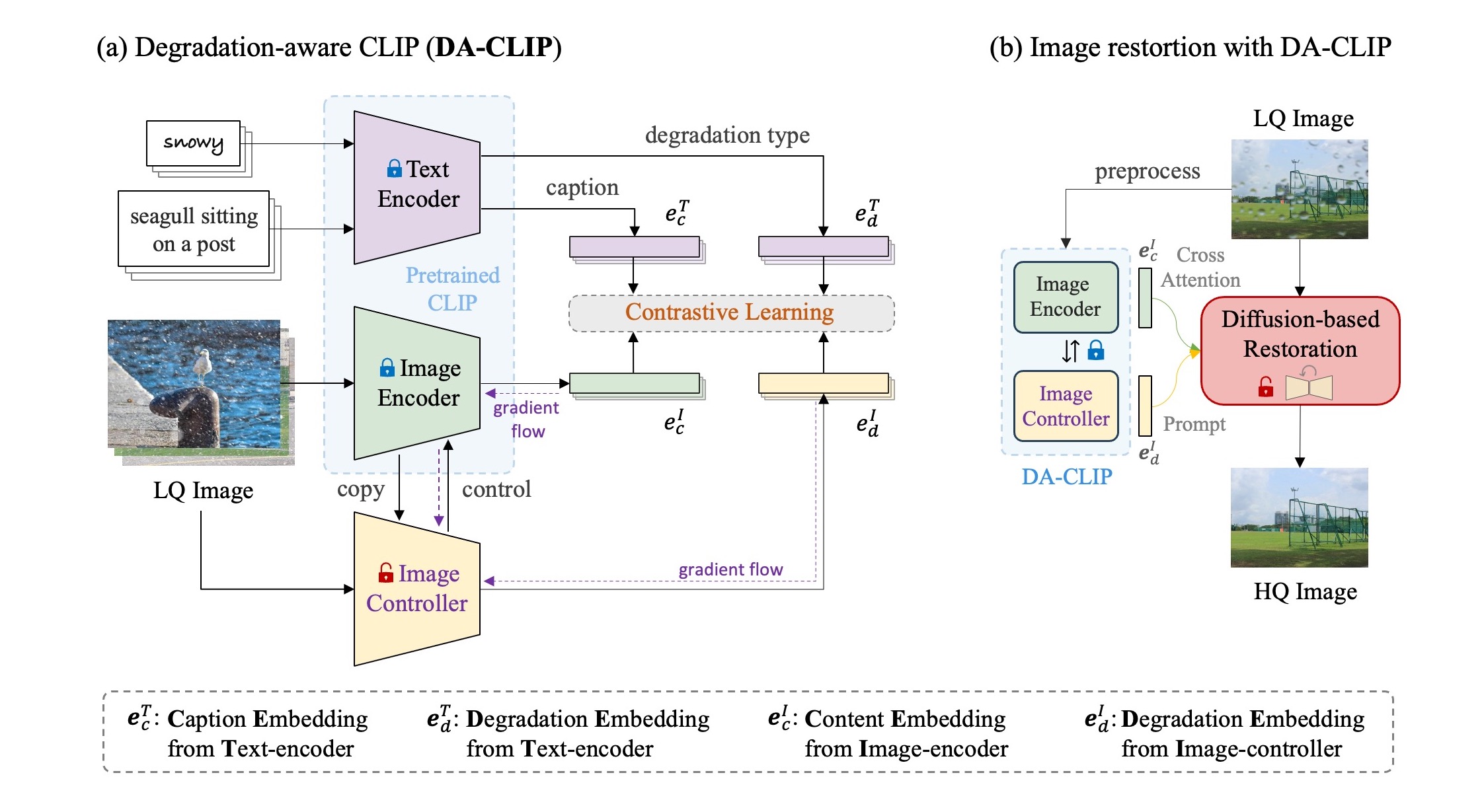
DA-CLIP freezes both the text and image encoders of a pre-trained CLIP but learns an additional image controller with contrastive learning. This controller predicts degradation features to match real corruptions and then controls the image encoder to output high-quality content features. Once trained, DA-CLIP can be integrated into other image restoration models by simply adding a cross-attention module and a degradation feature prompting module.
Controlling the ViT-based image encoder with a trainable controller. The dense connection layers from controller to image encoder are initialized to zero.
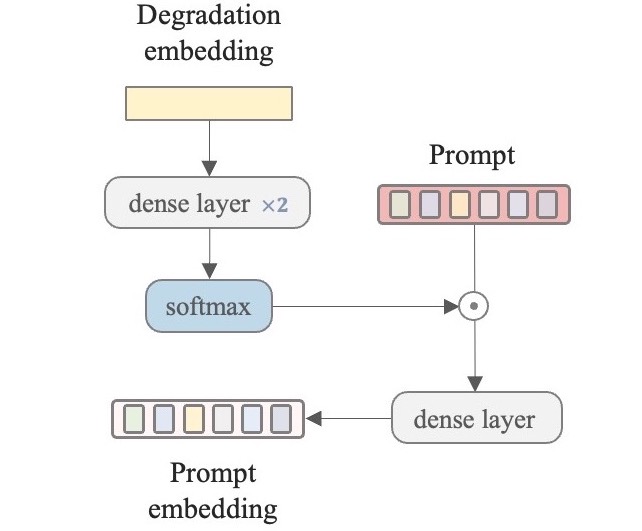
Learning the prompt with degradation embeddings predicted from the controller. The prompt module aims to improve the degradation classification for unified image restoration.
In order to train DA-CLIP on the mixed-degradation dataset, we use the bootstrapped vision-language framework BLIP to generate synthetic captions for all HQ images. Since the inputs are clean, the generated captions are assumed to be accurate and of high-quality. We are then able to construct image-text-degradation pairs by directly combining these clean captions, LQ images, and the corresponding degradation types.
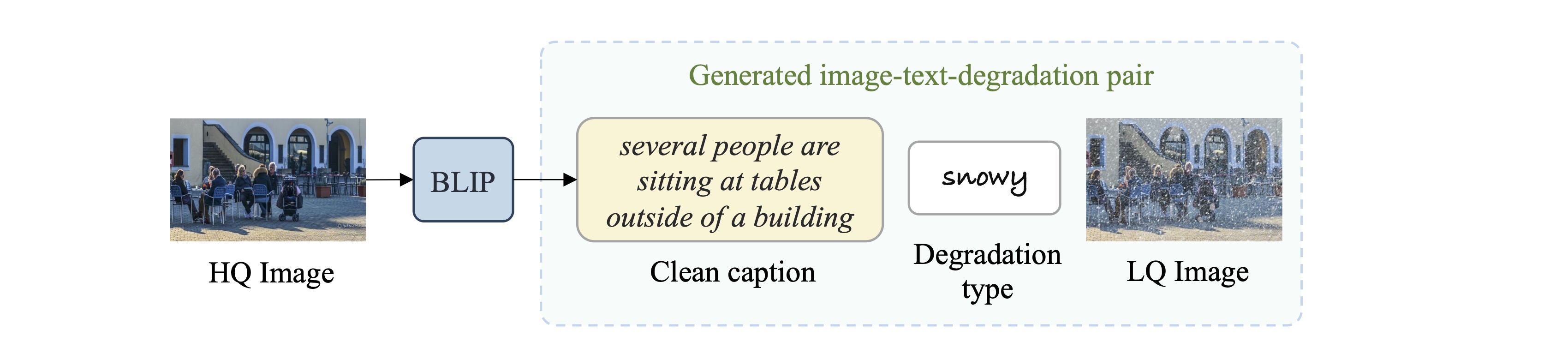
An example of generating the image-text-degradation tuple with BLIP. The clean caption generated from the HQ image is accurate and does not convey the degradation information.


If our code helps your research or work, please consider citing our paper. The following are BibTeX references:
@article{luo2023controlling,
title={Controlling Vision-Language Models for Universal Image Restoration},
author={Luo, Ziwei and Gustafsson, Fredrik K and Zhao, Zheng and Sj{\"o}lund, Jens and Sch{\"o}n, Thomas B},
journal={arXiv preprint arXiv:2310.01018},
year={2023}
}