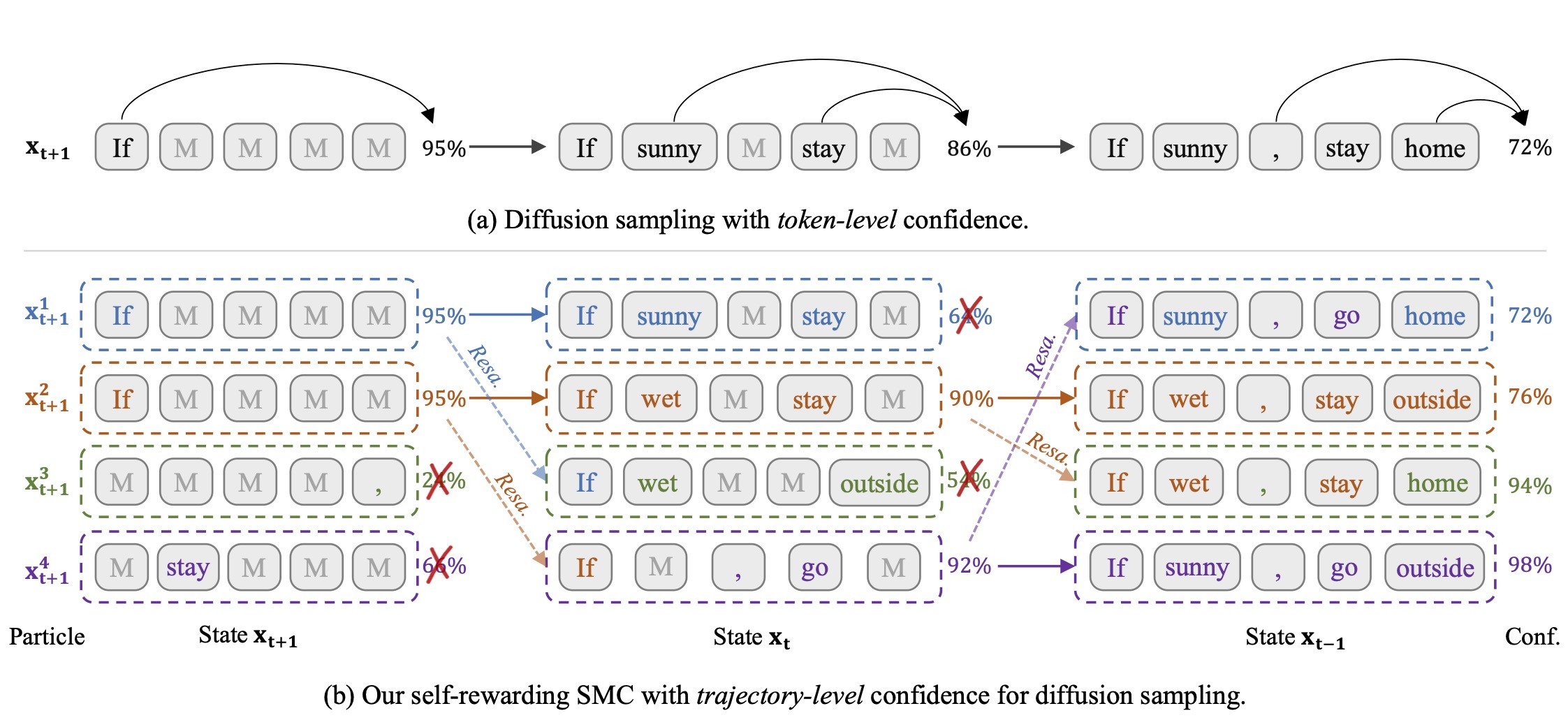
Self-Rewarding SMC for Masked Diffusion Language Models
TL;DR. Self-Rewarding SMC is an inference-time scaling method that leverages trajectory-level confidence from diffusion models as importance weights to steer generation toward globally confident, high-quality samples.